
描述
- 训练阶段:组委会提供25000条数据作为训练数据,参赛队伍报名后可从大赛官网下载训练数据集,并进行算法设计、训练和优化。
- 预赛阶段:组委会提供10万条数据作为预赛数据集。参赛队伍使用自己的算法,对这10万条数据进行“优化等级”标注。本竞赛将以优化等级标注的准确率作为选手预赛的得分。
- 分赛区决赛和全国总决赛阶段。组委会提供100万条正式比赛数据,参赛队伍使用自己的算法,对这100万条数据进行“优化等级”标注。本竞赛将以优化等级标注的准确率作为选手决赛的技术得分,结合决赛答辩评出最终名次。
- 详情见 http://117.50.29.62/pc/competition_topic.jsp
环境
| 环境 | 版本 | Python模块 | 版本 |
|---|---|---|---|
| Ubuntu | 16.04 | tensorflow | 1.8 |
| Anaconda | 5.1 | numpy | |
| Python | 3.6 | pandas | |
| Jupyter lab | 0.31.5 | matplotlib |
数据预处理
- 标签列为数字特征,不做处理。
- 数据中特征列有花色,牌面等信息为字母标注,将其替换成数字特征,模型相对比较容易处理。比如C替换成1,D替换成2等。如下列代码所示:
|
|
特征提取
- 前10列特阵列的数字特征
- 可以考虑使用交叉列输入神经网络
代码示例如下:
|
|
模型选择
- 神经网络采用三层隐藏层,神经元个数分别是1536,768,384
- 优化函数采用
ProximalAdagradOptimizer - 学习率0.005
- L1正则化率0.001
- L2正则化率0.001
具体代码如下:12345678910cls = tf.estimator.DNNClassifier( feature_columns=feature_columns, hidden_units=[1536,768,384], n_classes=numClasses, optimizer=tf.train.ProximalAdagradOptimizer( learning_rate=0.005, l1_regularization_strength=0.001, l2_regularization_strength=0.001 ))
模型训练与预测
对已有的数据进行2000次训练,准确率如下图,20分钟训练模型2000次准确率99.5%
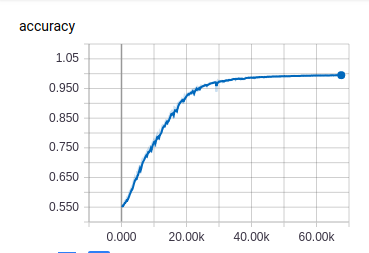
准确率
查看训练数据和预测数据分布
- 对数据进行预测并画出柱形图对比分布,如下图
- 大体可以看出分布是相同的
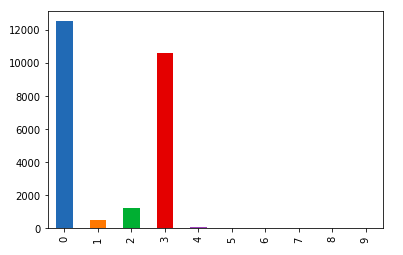
训练数据分布
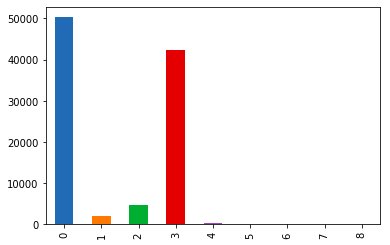
预测数据分布
提高
- 训练的数据有一定的规律,下一步考虑使用一定的规则来优化模型
